Apache Spark Tungsten
Project Tungsten은 Apache Spark의 성능을 책임지고 있는 아주 중요한 프로젝트 중의 하나입니다. Apache Spark 2.x 으로 업그레이드되면서 Phase 2 Tungsten Engine을 탑재했습니다. 지금까지 많은 연구논문이나 산업계에서는 시스템의 병목의 원인은 디스크 I/O나 네트워크에 있다고 보고 중점적으로 이 부분을 개선하려고 노력 했습니다. 이와는 다르게 Project Tungsten은 CPU와 Memory 개선에 중점을 두고 있습니다. 이번 포스팅에서는 Tungsten은 무엇이며 Spark 성능을 어떻게 개선 시키고 있는지 살펴보도록 하겠습니다.
Project Tungsten은 무엇인가?
Project Tungsten은 spark의 핵심적인 성능을 개선 시키기 위한 프로젝트로서, 메모리와 CPU 성능을 개선에 많은 중점을 두고 있습니다. Making sense of performance in data analytics framework 페이퍼에 의하면 Spark의 병목 원인은 CPU라는 걸 알 수 있습니다. 그 이유는 데이터를 compress/decompress 하거나 serialize/deserialize 하는 작업이 CPU 자원을 많이 사용하기 때문입니다. 예를 들어 parquet와 같은 압축 포맷을 사용하면 I/O는 줄어 들 수 있지만 데이터를 압축 하거나 풀때 CPU를 많이 사용합니다. 또한, Spark는 JVM을 기반으로 하는 Scala로 개발되어 있어 반드시 Java Object로 변환이 되어야 합니다. 디스크에서 읽은 데이터를 byte buffer에서 Java Object로 deserialize 해야 하는 작업이 필요합니다.
이러한 이유로 Tungsten이 집중적으로 개선 시키고자 하는 부분은 3가지입니다.
- Memory Management and Binary Processing
- Cache-aware computation
- Code Generation
Memory Management and Binary Processing
JVM을 기반으로 하는 Scala는 JVM의 기능들을 그대로 사용합니다. 한 예로 Scala에서는 내부적으로 Java String 객체를 사용합니다. 하지만 Java 객체는 메모리 오버헤드가 큽니다. 다시 말해 저장 공간을 많이 차지한다는 의미입니다. 예를 들어 “abcd”를 String 객체에 저장하면 48 bytes가 필요합니다. UTF-8(제가 작성한 인코딩 관련 여기) 로 인코딩하게 되면 단지 4 bytes 만 필요 합니다.
java -jar jol-cli-0.6-full.jar internals java.lang.String # Running 64-bit HotSpot VM. # Using compressed oop with 3-bit shift. # Using compressed klass with 3-bit shift. # Objects are 8 bytes aligned. # Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes] # Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes] java.lang.String object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) bb 15 14 43 (10111011 00010101 00010100 01000011) (1125389755) 12 4 char[] String.value [] 16 4 int String.hash 0 20 4 int String.hash32 0 Instance size: 24 bytes Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
위 화면은 Java Object Layout 툴로 Java String 객체의 layout scheme 정보를 출력한 화면 입니다. Header가 12 bytes가 필요하고 hash 코드값도 4 bytes 차지 하고 있습니다. 각각의 문자들을 UTF-16 으로 인코딩 하기 때문에 8 bytes가 필요하고 추가적으로 20 bytes가 필요 합니다. 총 48 bytes가 필요 합니다.
JVM의 또 다른 이슈는 garbage collection(a.k.a GC) 입니다. Heap 공간은 Young Generation과 Old Generation 으로 나뉩니다. 다시 Young Generation은 Eden과 Survivor Space을 영역으로 구성이 되어 있습니다.
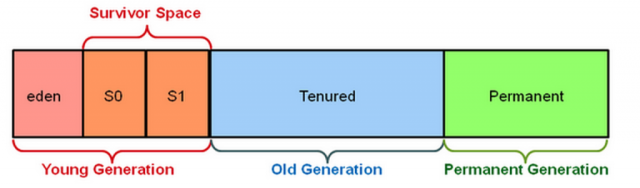
source : https://databricks.com/blog/2015/05/28/tuning-java-garbage-collection-for-spark-applications.html
새로 만들어진 객체는 Eden 영역에 생성이 되며 계속 살아 있는 객체들은 Survivor Space 으로 객체들을 이동 시키기 위해 minor GC가 발생 합니다. 그래도 여전히 Survivor Space 에 살아 남은 객체들이 있다면 Old Generation 으로 이동이 됩니다. Old Generation에 존재하는 객체들을 제거하기 위해 Major GC를 수행하는데 최소한으로 그리고 길게 수행되지 않도록 튜닝 작업을 해야 합니다. 왜냐하면 모든 thread가 Major GC가 끝날때 까지 아무일도 할 수 없기 때문입니다. 일명 Stop-The-world(STW) 이라고 합니다.
Tungsten은 위에서 설명드린 Java 객체의 오버헤드와 garbage collection 문제를 해결하기 위해 sun.misc.Unsafe를 사용 합니다. JVM의 heap memory 영역을 사용하지 않고 native 영역 메모리를 사용함으로써 Java object 오버헤드 및 GC 문제를 해결 했습니다.
sun.misc.Unsafe 는 JVM 에서 C-Style의 low-level 프로그래밍을 하기 위해 사용 되고 있으며, 이미 Netty, Cassandra, Akka, Neo4j 등 유명 프로젝트에서 많이 사용 되고 있습니다. 소문에 의하면 Java9에서는 sun.misc.Unsafe가 빠질 수 있다고 합니다.
Cache-aware Computation
Cache-aware Computation은 CPU L1/L2/L3 cache를 개선해서 데이터 처리 속도를 높이려는 목적이 있습니다. Spark를 프로파일링 해본 결과 CPU 시간이 main memory로 부터 데이터가 전송 되기 까지 기다리는 시간이 대부분 이였기 때문 입니다. Project Tungsten은 cache-locality를 개선 하기 위해 cache에 최적화된 Alpha Sort 알고리듬를 사용 했습니다.

위의 그림처럼 일반적인 데이터 정렬 작업시 레코드에 대한 포인터의 배열을 저장합니다(왼쪽 사각형이 포인터). 비교 작업은 메모리에 임의에 위치한 레코드를 가리키는 두 포인터를 참조 해야 되기 때문에 캐쉬 적중률이 낮습니다.

source : http://research.microsoft.com/en-us/um/people/gray/papers/AlphaSortSigmod.pdf
Alpha sort에서 고안한 방법은 레코드의 정렬키를 포인터와 같이 저장하는 방법 입니다. 비교 작업시 레코드를 가리키는 포인터를 참조 하지 않아도 되기 때문에 cache locality를 개선 시킬 수 있어 속도 향상을 기대할 수 있습니다.
Code Generation
SELECT COUNT(*) FROM store_sales WHERE ss_item_sk = 1000
Spark 1.x 버젼까지는 위에서 보는 쿼리를 evaluation 하기 위해 DBMS에서 표준처럼 사용하고 있는 Valcano Model 을 사용했습니다. Volcano Model 에서 쿼리는 여러 operator로 구성이 되고 하나의 튜플을 다음 연산자로 반환하는 next 인터페이스가 있습니다.
class Filter(child: Operator, predicate: (Row = Boolean))extends Operator {
def next(): Row = {
var current = child.next()
while (current == null || predicate(current)) {
current = child.next()
}
return current
}
}
만약에 대학교에 갓 입학한 컴퓨터 과학 학생들에게 위의 쿼리를 코딩 하라고 하면 아마 아래처럼 코딩할 가능성이 큽니다. 무척이나 간단해 보이지만 성능 측면 에서는 위에서 설명한 Volcano model 보다 훨씬 빠르게 수행 됩니다.
var count = 0
for (ss_item_sk in store_sales) {
if (ss_item_sk == 1000) {
count += 1
}
}
그 이유는 Volcano model은 여러 이슈가 있지만 그 중에서 polymorphic function dispatches 문제 때문 입니다. Scala 컴파일 시에는 Operator interface의 next 메소드를 확인 하지만 런타임시에는 Operator interface의 next를 구현한 Filter 클래스의 next를 확인 합니다. 이처럼 Scala 에서는 어떤 메소드를 실행 시킬 지 결정하기 위해 virtual table(vtable)을 관리 하는데 이를 확인 하는 행위 자체가 무지 느립니다. 하지만 갓 입학한 대학생이 만든 코드는 오로지 하나의 메소드에서 모든것을 구현하고 있기 때문에 vtable 뒤지는 행위가 없어 수행속도가 오히려 빠릅니다. 아래 표처럼 college freshman 코드가 훨씬 빠르다는 것을 확인 할 수 있습니다.

이러한 이유 때문에 Tungsten은 대학생의 코딩 스타일을 generation 하고, 굉장히 가볍고 컴파일이 빠른 Janino compiler를 이용해서 JVM byte 코드를 생성 합니다. Volcano model 처럼 operator를 나누는 것이 아니라 하나의 메소드 안에서 모든것이 수행 될 수 있도록 합니다.
Conclusion
개인적인 호기심에 Tungsten 자료를 정리하다 혼자 보기 아까워 팀 내 공유를 했었고 Spark 사용자에게 분들에게도 좋은 정보가 될 거 같아 본격적으로 블로그를 시작하게 되었습니다. 예전부터 블로그를 하려고 했으나 시간이 없다는 핑계로 시작도 못 했다가 Project tungsten 덕분에 이렇게 블로그를 시작하게 되었습니다. 처음으로 작성한 포스팅이라 부족하겠지만, 아무쪼록 보시는 분들에게 도움이 되었으면 하는 바람입니다.
참고 사이트
https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html
https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
https://people.eecs.berkeley.edu/~keo/publications/nsdi15-final147.pdf
https://deanwampler.github.io/polyglotprogramming/papers/ScalaJVMBigData-SparkLessons.pdf

잘봤습니다!
LikeLike
감사합니다
LikeLike
잘 읽었습니다~
LikeLike
좋은 내용 감사합니다.
LikeLike
아무쪼록 도움이 되었으면 합니다
LikeLike